이 글에서는 PolarDB HTAP 구조에 대해서 설명합니다.
목차
- PolarDB HTAP 소개
- Basic Principles of HTAP
- Distributed Optimizer
- Parallelism of Operators
- SQL Statement-level Scalability
- Transactional Consistency
PolarDB HTAP 소개
PolarDB의 공유 스토리지는 스토리지 풀로 구성됩니다.
읽기/쓰기 분할이 활성화된 경우, 공유 스토리지가 지원하는 이론적인 I/O 처리량은 무한대입니다. 하지만 대용량 쿼리는 개별 컴퓨트 노드에서만 실행할 수 있으며, 단일 컴퓨트 노드의 CPU, 메모리, I/O 사양이 제한되어 있습니다. 따라서 단일 컴퓨팅 노드로는 공유 스토리지가 지원하는 높은 I/O 처리량을 충분히 활용하거나 더 많은 컴퓨팅 리소스를 확보하여 대규모 쿼리를 가속화할 수 없습니다. 이러한 문제를 해결하기 위해 PolarDB는 공유 스토리지 기반 MPP 아키텍처를 사용하여 OLTP 시나리오에서 OLAP 쿼리를 가속화합니다.
Basic Principles of HTAP
PolarDB 클러스터에서는 물리적 스토리지가 모든 컴퓨팅 노드 간에 공유됩니다. 따라서 기존 MPP 데이터베이스에서 테이블을 스캔하는 방법을 사용하여 PolarDB 클러스터의 테이블을 스캔할 수 없습니다. PolarDB는 독립 실행형 실행 엔진에서 MPP를 지원하며 최적화된 공유 스토리지를 제공합니다. 이 공유 스토리지 기반 MPP 아키텍처는 업계 최초의 아키텍처입니다. PolarDB를 사용하기 전에 이 아키텍처의 기본 원칙을 숙지하는 것이 좋습니다:
- 셔플 연산자는 데이터 배포를 마스킹합니다.
- ParallelScan 연산자는 공유 스토리지를 마스킹합니다.

테이블 A와 테이블 B가 조인되고 집계됩니다.
테이블 A와 테이블 B는 여전히 공유 스토리지에서 개별 테이블입니다. 이러한 테이블은 물리적으로 파티션되지 않습니다.
네 가지 유형의 스캔 연산자가 공유 스토리지의 테이블을 가상 파티션으로 스캔하도록 재설계되었습니다.
Distributed Optimizer
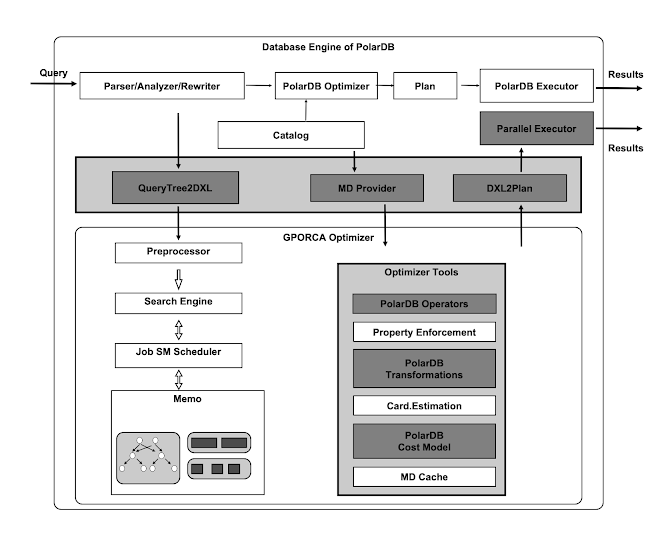
GPORCA 옵티마이저는 공유 스토리지를 인식할 수 있는 일련의 변환 규칙을 제공하도록 확장되었습니다. GPORCA 옵티마이저를 사용하면 PolarDB가 특정 양의 계획된 검색 공간에 액세스할 수 있습니다. 예를 들어, PolarDB는 테이블을 전체 또는 다른 가상 파티션으로 스캔할 수 있습니다. 이것이 공유 스토리지 기반 MPP와 기존 MPP의 주요 차이점입니다.
다음 그림의 상단에서 회색으로 표시된 모듈은 데이터베이스 엔진의 모듈입니다. 이러한 모듈을 통해 PolarDB의 데이터베이스 엔진은 GPORCA 옵티마이저와 동작 할 수 있습니다.
다음 그림의 하단에 있는 모듈은 GPORCA 최적화기를 구성하는 모듈입니다. 이 모듈 중 회색으로 표시된 모듈은 확장 모듈로, GPORCA 옵티마이저가 PolarDB의 공유 스토리지와 통신할 수 있게 해줍니다.

Parallelism of Operators
PolarDB의 네 가지 연산자 유형에는 병렬 처리가 필요합니다. 이 섹션에서는 순차 스캔을 실행하는 데 사용되는 연산자에 대해 병렬 처리를 활성화하는 방법을 설명합니다. 공유 스토리지에서 지원되는 I/O 처리량을 최대한 활용하기 위해 PolarDB는 순차 스캔 중에 각 테이블을 논리적 단위로 분할합니다.
각 단위에는 4MB의 데이터가 포함됩니다. 이렇게 하면 PolarDB는 I/O 로드를 여러 디스크에 분산할 수 있으며, 디스크는 동시에 데이터를 스캔하여 순차 스캔을 가속화할 수 있습니다. 또한 각 읽기 전용 노드는 모든 테이블이 아닌 특정 테이블만 스캔하면 됩니다. 캐시할 수 있는 테이블의 크기는 모든 읽기 전용 노드의 버퍼 풀의 총 크기입니다.

- 읽기 전용 노드를 생성하여 스캔 성능을 30배까지 향상시킬 수 있습니다.
- 버퍼링 기능을 활성화하여 스캔에 필요한 시간을 37분에서 3.75초로 단축할 수 있습니다.

SQL Statement-level Scalability
데이터 공유는 클라우드 네이티브 환경에서 최고의 확장성을 제공하는 데 도움이 됩니다. 코디네이터 노드의 전체 경로에는 다양한 모듈이 포함되며, PolarDB는 이러한 모듈의 외부 종속성을 공유 스토리지에 저장할 수 있습니다. 또한 작업자 스레드의 전체 경로에는 여러 운영 매개변수가 포함되며, PolarDB는 제어 경로를 통해 코디네이터 노드에서 이러한 매개변수를 동기화할 수 있습니다. 이렇게 하면 코디네이터 노드와 작업자 스레드가 stateless 상태가 됩니다.

stateless가 된다는 것은 어느 위치에서 언제든지 실행할 수 있다는 것을 의미합니다.
분석을 바탕으로 다음과 같은 결론을 내렸습니다:
- SQL 조인을 실행하는 모든 읽기 전용 노드는 코디네이터 노드로 작동할 수 있습니다. 따라서 PolarDB의 성능은 더 이상 단일 코디네이터 노드에 제한되지 않습니다.
- 각 SQL 문은 모든 컴퓨팅 노드에서 원하는 수의 워커 스레드를 시작할 수 있습니다. 따라서 컴퓨팅 성능이 향상되고 워크로드를 보다 유연하게 예약할 수 있습니다. 서로 다른 컴퓨팅 노드에서 서로 다른 종류의 워크로드를 동시에 실행하도록 PolarDB를 구성할 수 있습니다.
Transactional Consistency

'DBMS' 카테고리의 다른 글
| HTAP OLAP과 OLTP 지원 DBMS의 기술 분석 - 1[HTAP Databases: What is New and What is Next] (0) | 2023.11.28 |
|---|---|
| NoSQL이란 무엇인가? (0) | 2023.11.27 |
| PolarDB 아키텍처 세부: Low-latency Replication (0) | 2023.11.25 |
| PolarDB 아키텍처 세부: 컴퓨팅-스토리지 분리 (Compute-Storage Separation Challenges of Shared Storage) (0) | 2023.11.25 |
| PolarDB for PostgreSQL 오픈 소스 분석 - 아키텍처 (0) | 2023.11.25 |










